Apr 2021 Prof. Yun Zhang’s paper “Deep Learning Based Just Noticeable Difference and Perceptual Quality Prediction Models for Compressed Video” was accepted by IEEE Transactions on Circuits and Systems for Video Technology.
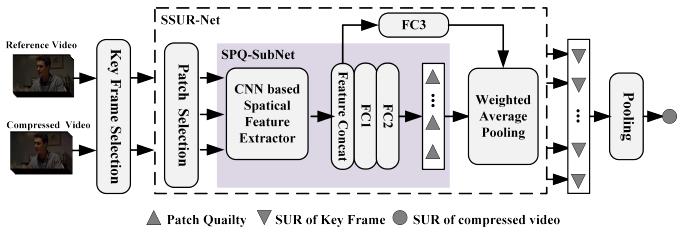
Fig. 1 The framework of VW-SSUR.
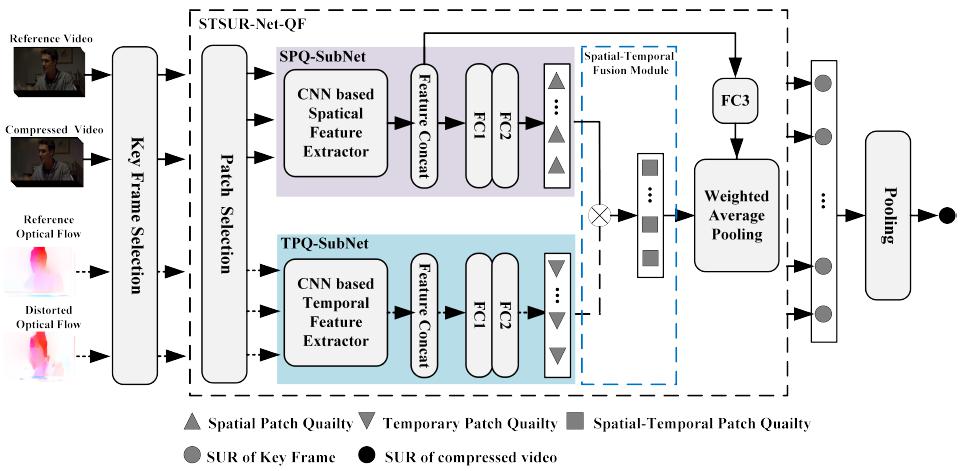
Fig. 2 The proposed VW-STSUR-QF based SUR prediction framework.
Human visual system has a limitation of sensitivity in detecting small distortion in an image/video and the minimum perceptual threshold is so called Just Noticeable Difference (JND). JND modelling is challenging since it highly depends on visual contents and perceptual factors are not fully understood. In this paper, we propose deep learning based JND and perceptual quality prediction models, which are able to predict the Satisfied User Ratio (SUR) and Video Wise JND (VWJND) of compressed videos with different resolutions and coding parameters. Firstly, the SUR prediction is modeled as a regression problem that fits deep learning tools. Then, Video Wise Spatial SUR method (VWSSUR) is proposed to predict the SUR value for compressed video, which mainly considers the spatial distortion. Thirdly, we further propose Video Wise Spatial-Temporal SUR (VW-STSUR) method to improve the SUR prediction accuracy by considering the spatial and temporal information. Two fusion schemes that fuse the spatial and temporal information in quality score level and in feature level, respectively, are investigated. Finally, key factors including key frame and patch selections, cross resolution prediction and complexity are analyzed. Experimental results demonstrate the proposed VW-SSUR method outperforms in both SUR and VWJND prediction as compared with the state-of-the-art schemes. Moreover, the proposed VW-STSUR further improves the accuracy as compared with the VW-SSUR and the conventional JND models, where the mean SUR prediction error is 0.049, and mean VWJND prediction error is 1.69 in quantization parameter and 0.84 dB in peak signal-to-noise ratio.