

 |
Joint Source-Channel Decoding of Polar Codes forHEVC based Video Streaming
[PDF]
Jinzhi Lin,Yun Zhang(*Corresponding Author), Na Li, and Hongling Jiang ACM Transactions on Multimedia Computing, Communications, and Applications (ACM TOMM) , 2021, Accepted. |
|
Ultra High-Definition (UHD) and Virtual Reality (VR) video streaming over 5G networks are emerging, in which High-Efficiency Video Coding (HEVC) is used as source coding to compress videos more efficiently and polar code is used as channel coding to transmit bitstream reliably over an error-prone channel. In this paper, a novel Joint Source-Channel Decoding (JSCD) of polar codes for HEVC based video streaming is presented to improve the streaming reliability and visual quality.Firstly, a Kernel Density Estimation (KDE) fitting approach is proposed to... | |
 |
Deep Learning Based Just Noticeable Difference and Perceptual Quality Prediction Models for Compressed Video
[PDF]
Yun Zhang, Huanhua Liu, You Yang, Xiaoping Fan, Sam Kwong, C. C. Jay Kuo IEEE Transactions on Circuits and Systems for Video Technology (IEEE T-SCVT) , 2021, Accepted. |
|
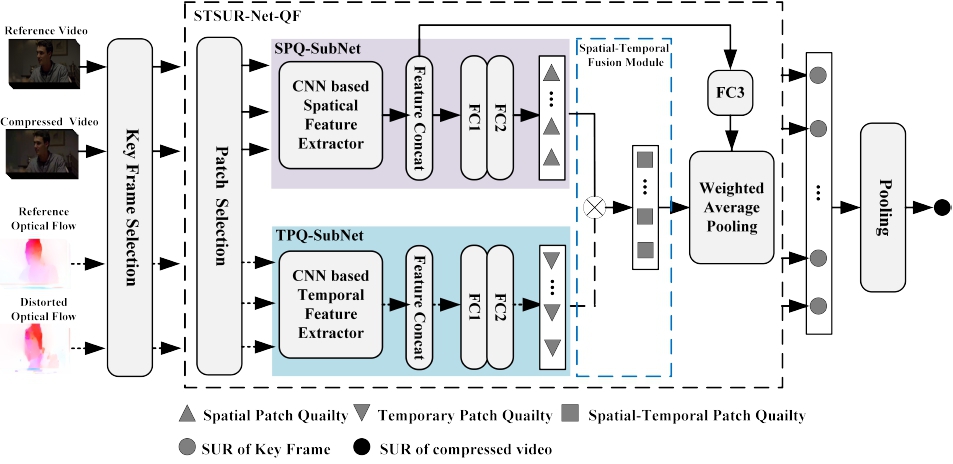
Human visual system has a limitation of sensitivity in detecting small distortion in an image/video and the minimum perceptual threshold is so called Just Noticeable Difference (JND). In this paper, we propose deep learning based JND and perceptual quality prediction models, which are able to predict the Satisfied User Ratio (SUR) and Video Wise JND (VWJND) of compressed videos with different resolutions and coding parameters. Firstly, the SUR prediction is modeled as a regression problem that fits deep learning tools. Then, Video Wise Spatial SUR method (VWSSUR) is proposed to predict... | |
 |
Subjective Quality Database and Objective Study of Compressed Point Clouds with 6DoF Head-mounted Display
[PDF]
Xinju Wu, Yun Zhang,Chunling Fan, Junhui Hou,Sam Kwong IEEE Transactions on Circuits and Systems for Video Technology (IEEE T-SCVT) , 2021, Accepted. |
|
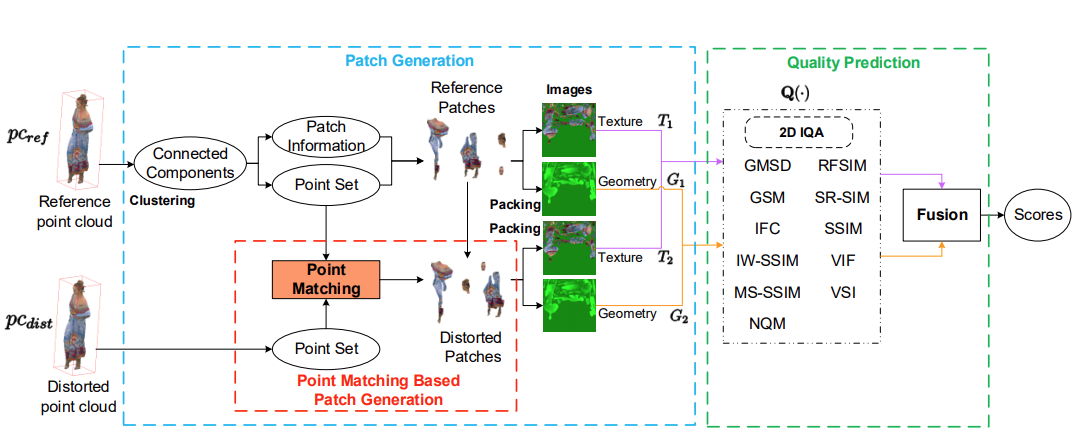
In this paper, we focus on subjective and objective Point Cloud Quality Assessment (PCQA) in an immersive environment and study the effect of geometry and texture attributes in compression distortion. Using a Head-Mounted Display (HMD) with six degrees of freedom, we establish a subjective PCQA database, named SIAT Point Cloud Quality Database (SIAT-PCQD). Our database consists of 340 distorted point clouds compressed by the MPEG point cloud encoder with the combination of 20 sequences and 17 pairs of geometry and texture quantization parameters. The impact of distorted geometry ... | |
 |
Projection Invariant Feature and Visual Saliency-Based Stereoscopic Omnidirectional Image Quality Assessment
[PDF]
Xuemei Zhou, Yun Zhang*, Na Li, Xu Wang, Yang Zhou, Yo-Sung Ho IEEE Transactions on Broadcasting (T-BC) , 2021, Accepted. |
|
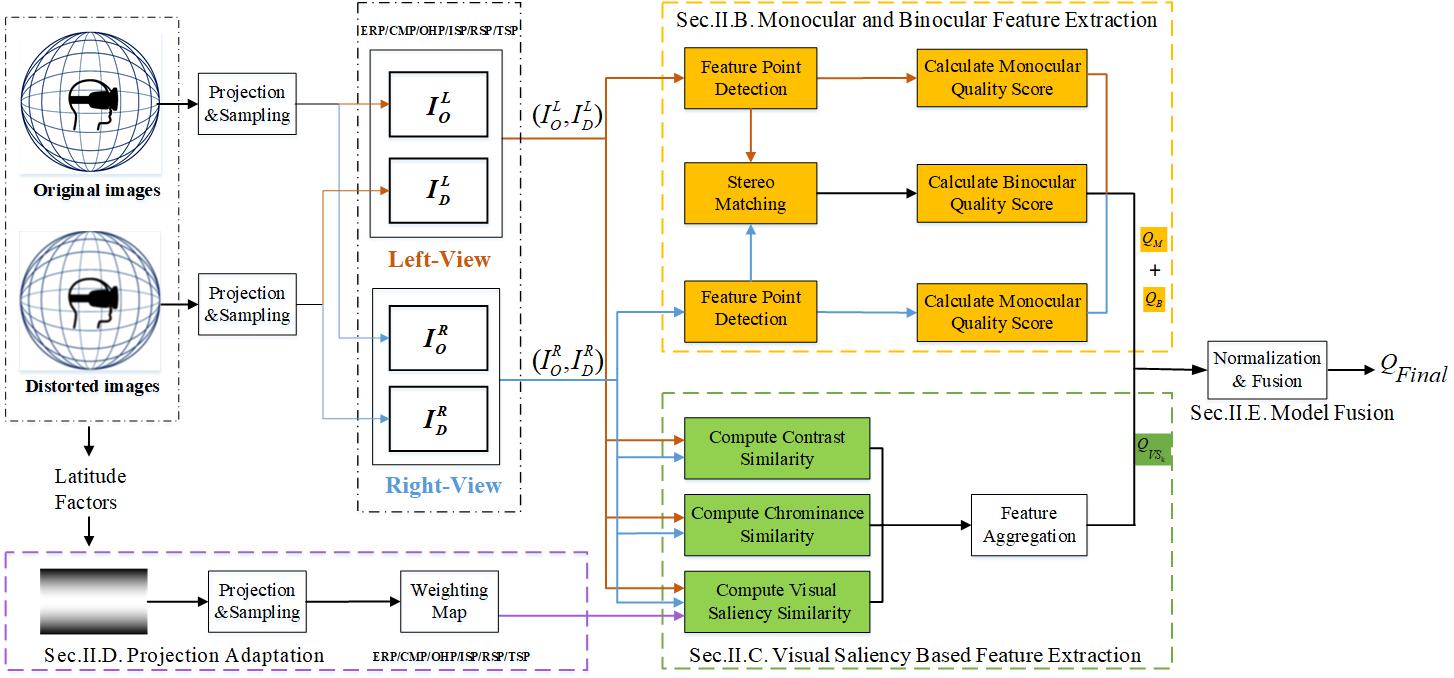
In this paper, we propose a quality assessment model based on the projection invariant feature and the visual saliency for Stereoscopic Omnidirectional Images (SOIs). Firstly, monocular and binocular features of SOI, as the projection invariant feature, are derived from the Scale-Invariant Feature Transform (SIFT) points to tackle the inconsistency between the stretched projection formats and the viewports. Secondly, the visual saliency model, combined with the perceptual factors, i.e., the chrominance and contrast, facilitates the prediction accuracy.Thirdly, according to the characteristics of the panoramic... | |
 |
Highly Efficient Multiview Depth Coding Based on Histogram Projection and Allowable Depth Distortion
[PDF]
Yun Zhang*, Linwei Zhu, Raouf Hamzaoi, Sam Kowng, Yo-Sung Ho IEEE Transactions on Image Processing (IEEE T-IP), vol.30, pp.402-417, 2021 |
|
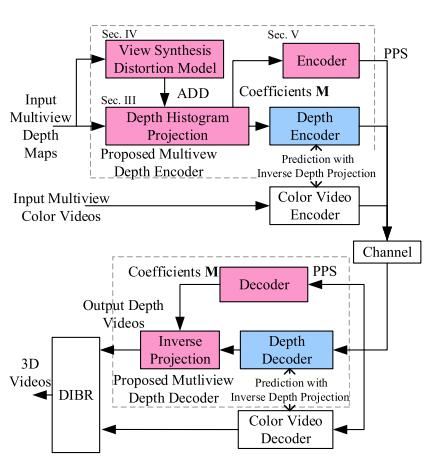
Mismatches between the precisions of representing the disparity, depth value and rendering position in 3D video systems cause redundancies in depth map representations. In this paper, we propose a highly efficient multiview depth coding scheme based on Depth Histogram Projection (DHP) and Allowable Depth Distortion (ADD) in view synthesis. Firstly, DHP exploits the sparse representation of depth maps generated from stereo matching to reduce the residual error from INTER and INTRA predictions in depth coding. We provide a mathematical foundation for DHP-based lossless depth coding by theoretically analyzing its rate-distortion cost. Then, due to the mismatch between depth value and rendering position... | |
  |
Online Learning-Based Multi-Stage Complexity Control for Live Video Coding
[PDF]
Chao Huang, Zongju Peng, Yong Xu, Fen Chen, Qiuping Jiang, Yun Zhang, Gangyi Jiang, and Yo-Sung Ho IEEE Transactions on Image Processing (IEEE T-IP), vol.30, pp.641-656, 2021.11 |
|
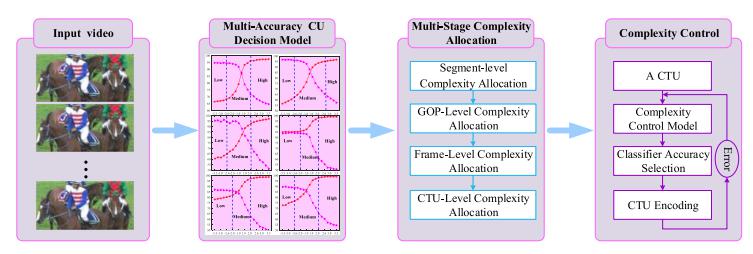
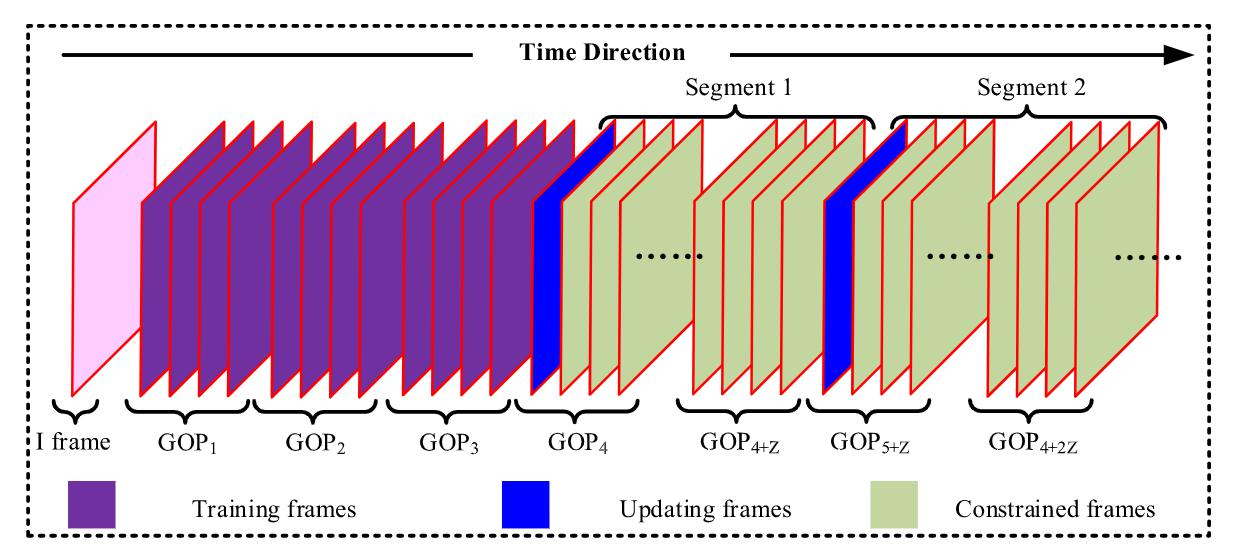
High Efficiency Video Coding (HEVC) can significantly improve the compression efficiency in comparison with the preceding H.264/Advanced Video Coding (AVC) but at the cost of extremely high computational complexity. Hence, it is challenging to realize live video applications on low-delay and power-constrained devices, such as the smart mobile devices. In this article, we propose an online learning-based multi-stage complexity control method for live video coding. The proposed method consists of three stages: multi-accuracy Coding Unit (CU) decision, multi-stage complexity allocation, and Coding Tree Unit (CTU) level complexity control. Consequently, the encoding complexity can be accurately controlled... |